
List인터페이스
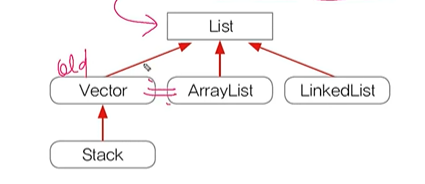
List는 순서가 있고 중복을 허용하는 데이터의 집합에 속하며(선형 자료구조), 같은 선형 자료구조에 속하는 배열과 달리 동적 자료구조로 정적으로 크기를 할당하여 사용하지 않고 List 인터페이스를 구현한 컬렉션 클레스는 동적으로 크기를 할당하여 사용한다.
- List인터페이스를 구현한 대표적인 컬렉션 클래스
ArrayList
LinkedList
Vector
* Vector와 ArrayList는 비슷하지만 Vector을 계선한 것이 ArrayList로 ArrayList와 LinkedList가 대표적인 클래스이다.
Stack
List 인터페이스의 메서드
List는 Collection의 자손이기 때문에 Collection인터페이스의 메서드를 포함하고 있다.
| 메서드 | 설명 |
| void add (int index, Object element) boolean addAll(int index, Collection c) |
지정된 위치(index)에 객체(element) 또는 컬렉션에 포함된 객체들을 추가한다. |
| Object get(int index) | 지정된 위치(index)에 있는 객체를 반환한다. |
| int indexOf(Object o) | 지정된 객체의 위치(index)를 반환한다. (List의 첫 번째 여소부터 순방행으로 찾는다.) |
| int lastIndexOf(Object o) | 지정된 객체의 위치(index)를 반환한다. (List의 마지막 요소부터 역방향으로 찾는다.) |
| ListIterator listIterator() ListIterator listIterator(int index) |
List의 객체에 접근할 수 있는 ListIterator를 반환한다. |
| Object remove(int index) | 지정된 위치(index)에 있는 객체를 삭제하고 삭제된 객체를 반환한다. |
| Object set(int index, Object element) | 지정된 위치(index)에 객체(element)를 저장한다. |
| void sort(Comparator c) | 지정된 비교자(comparator)로 List를 정렬한다. |
| List subList(int fromIndex, int toIndex) | 지정된 범위(fromIndex부터 toIndex)에 있는 객체를 반환한다. |
ArrayList 클래스
ArrayList 클래스는 내부적으로 Object[] 배열을 이용하여 요소를 저장하기 때문에 객체만 저장이 가능하지만 최상위 타입인 Object 타입으로 배열을 생성하기 때문에 인데스를 이용해 배열 요소에 빠르게 접근할 수 있다.
하지만 배열은 크기를 변경할 수 없기 때문에 크기를 늘리기 위해서는 새로운 배열을 생성하고 기존의 요소들을 옮겨야 하는 복잡한 과정을 거쳐야 한다. 따라서 요소의 추가 및 삭제에 걸리는 시간이 길어지는 단점이 있다.
ArrayList는 기존의 Vector를 개선한 것이다.
ArrayList와 Vector은 기능적으로 동일하지만 ArrayList는 동기화처리가 되어있지 않지만 Vector은 자체적으로 동기화처리가 되어 있다는 차이가 있다.
- List 인터페이스를 구현하기 때문에 저장순서가 유지되고 중복을 허용한다.
- 데이터의 저장공간으로 배열을 사용한다.
오토박싱에 의해 기본형이 참조형으로 자동변환되어 저장된다.
ArrayList list1 = new ArrayList(10);
list1.add(new Integer(5));
list1.add(5);ArrayList에 저장된 객체의 삭제 : ArrayLisy에 저장된 데이터를 세 번째 데이터를삭제하는 과정
list.remove(2)를 호출.
list1.remove(2);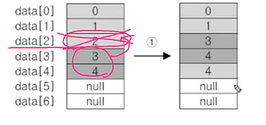
1. 삭제할 데이터 아래의 데이터를 한 칸씩 위로 복사해서 삭제할 데이터를 덮어쓴다.
System.arraycopy(data, 3, data, 2, 2);arraycopy() 메서드는 배열을 복사하는 메서드로 배열 data의 3번째 데이터부터 2개의 데이터를 복사하여 data의 2번째 부터 복사하는 것을 의미한다.
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
// src : 원본 배열
// srcPos : 원본 배열에서 복사 시작 인덱스
// dest : 대상 배열
// destPos : 대상 배열에서 복사 시작 인덱스
// length : 복사할 개수2. 데이터가 모두 한 칸씩 이동했으므로 마지막 데이터는 null로 변경한다.
data[size-1] = null;3. 데이터가 삭제되어 데이터의 개수가 줄었으므로 size의 값을 감소시킨다.
size--;- 마지막 데이터를 삭제하는 경우 첫번째 과정의 배열의 복사는 필요가 없다.
첫 번째 객체부터 삭제하는 경우 배열의 복사가 발생하여 제대로된 결과를 얻을 수 없다.

for(int i = 0; i<list1.size(); i++) {
list1.remove(i);
}마지막 객체부터 삭제하는 경우 배열의 복사가 발생하지 않기 때문에 속도가 빠르며 원하는 결과를 얻을 수 있다.
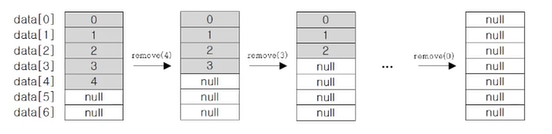
for(int i = list1.size(); i >= 0; i--) {
list1.remove(i);
}중간의 요소의 삽입, 삭제가 일어나는 경우 그 뒤의 요소들을 한칸씩 밀거나 당겨야 하기 때문에 삽입, 삭제시 비효율적이다.
ArrayList의 생성자와 주요 메서드
| 생성자 | 설명 |
| ArrayList() | 기본 크기가 10인 배열을 생성한다. |
| ArrayList(Collection c) | 컬렉션에 저장되어 있는 데이터를 저장하는 배열을 생성한다. |
| ArrayList(int initialCapacity) | 배열의 기본 크기를 지정 한다. 배열이 다 차면 기본 크기만큼 사이즈가 증가한다. |
| ArrayList<제네릭>() | 배열 값의 타입을 지정한다. |
| 메서드 | 설명 |
| boolean add(Object o) | 객체를 추가하는 메서드,추가 성공시 true를 실패시 false를 반환 |
| void add(int index, Object element) | 저장 위치를 지정하여 추가한다. |
| boolean addAll(Collection c) | 컬렉션이 가지는 요소를 그대로 저장한다. |
| boolean addAll(int index, Collection c) | 저장 시작 위치를 지정하여 추가 컬렉션 요소를 그대로 저장한다. |
| boolean remove(Object o) | 특정 요소를 삭제한다. |
| Object remove(int index) | 특정 위치의 요소를 삭제한다. |
| boolean removeAll(Collection c) | 요소중 컬렉션의 요소와 동일한 요소를 전부 제거한다. |
| void clear() | 모든 요소를 삭제한다. |
| int indexOf(Object o) | 객체의 위치를 찾아 인덱스를 반환한다. |
| int lastIndexOf(Object o) | 뒤에서부터 객체의 위치를 찾아 인덱스를 반환한다 |
| boolean contains(Objects o) | 객체가 존재하는지 확인후 true/false를 반환한다. |
| Object get(int index) | 해당 위치의 객체를 읽어온다. |
| Object set(int index, Object element) | 해당 위치의 객체를 변경한다. |
| List subList(int fromIndex, int toIndex) | 기존의 ArrayList 로부터 새로운 ArrayList 를 생성한다. (fromIndex <= x < toIndex) |
| Object[] toArray() | ArrayList에 저장된 객체를 객체배열(Object[])로 반환한다. |
| Object[] toArray(Object[] a) | 지정된 배열에 ArrayList의 요소를 저장해서 반환한다. |
| boolean isEmpty() | ArrayList의 요소가 있는지 확인한다. |
| void trimToSize() | 빈공간 제거한다. |
| int size() | 저장된 요소의 개수를 반환한다. |
LinkedList 클래스
LinkedList 클래스는 ArrayList 클래스가 배열을 이용하여 요소를 저장함으로써 발생하는 단점을 극복하기 위해 고안되었다.

ArrayList은 구조가 간단하고 데이터를 읽는데 걸리는 시간이 짧다는 장점이 있다.
- 첫번째 요소를 읽어오는 것과 마지막 요소를 읽어 오는 접근 시간은 동일하다.
하지만 크기를 변경할 수 없다는 단점과 비순차적인 데이터의 추가, 삭제에 시간이 많이걸린다는 단점이 있다.
- 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터를 복사해야한다.
- 크기 변경을 피하기 위해 충분히 큰 배열을 생성하면, 메모리가 낭비된다.
- 데이터를 추가하거나 삭제하기 위해, 다른 데이터를 옮겨야 한다.
- 그러나 순차적인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다.
이러한 배열의 단점을 보완하기 위해 LikedList를 사용한다.

배열은 저장된 요소가 순차적으로 저장되지만 배열과 달리 LinkedList는 비순차적으로 존재하는 요소를 연결한다. 요소를 노드라 부르며 노드에는 데이터와 자신의 다음 노드를 찾아가기 위해 다음 노드의 주소를 저장하기 위한 참조변수가 존재한다.
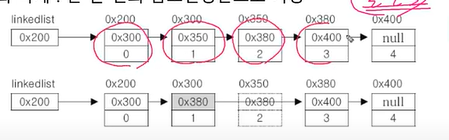
class Node{
Node next;
Object obj;
}예를 들어 배열이 하나의 큰 박스 한다면 박스가 가득 찼을때 박스에 물건을 추가하고 싶다면 박스의 물건을 전부 꺼낸뒤 다른 큰 박스에 옮기고 물건을 추가해야 한다.

반면 리스트는 기차와같이 여러 열차칸(요소)를 여러개 연결(다음 노드의 주소)하는 것과 비슷하다.

만약 새로운 열차칸(요소)을 연결하고 싶다면 끝에 추가만 하면 되며

새로운 연차칸(요소)을 중간에 추가하고 싶다면 연결을 변경만 하면 된다.

ArrayList은 각 요소가 연속적이라 변경하기 어렵지만 불연속적인 LinkedList는 각 개별 요소들은 연결해 놓은 것이기 때문에 변경에 유리하다.
위의 예시와 같이 데이터의 추가하고자 한다면 노드객체를 생성한뒤 두번의 참조변경만 한다면 추가할 수 있으며 삭제를 하고자 한다면 단순히 한번의 참조의 변경만을 하면 된다.(참조가 없는 데이터는 가비지컬렉터에 의해 삭제된다.)
LinkedList의 불연속적이라는 특징은 위와 같은 장점만 있는 것이 아니다. 데이터의 접근성이 나쁘다는 단점도 존재한다.
배열은 연속적이기 때문에 다음 요소의 주소를 정확히 알 수 있어 데이터에 대한 접근이 시간이 마지막 요소나 첫번째 요소나 동일하지만 다음 요소를 가리키는 참조(주소)만을 가지는 단일 연결 리스트(singly linked list)의 각 요소는 자신의 다음 요소에 대한 주소값 만을 기억하기 때문에 마지막 요소에 접근 하고자 한다면 모든 요소를 거쳐야 하며 현재 요소에서 이전 요소로 접근하기가 어렵다.

따라서 이런 나쁜 접근정을 개선해 접근성을 향상시킨 이중 연결리 스트(doubly linked list)를 많이 사용한다.
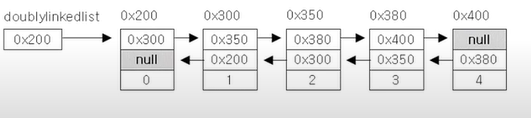
class Node{
Node next;
Node previous;
Object obj;
}이중 연결리스트는 다음 요소의 주소만을 가지는 링크드 리스트와 달리 다음 요소의 주소와 이전 요소의 주소, 두개의 주소를 가지고 있다. 요소 추가시 더 많은 참조의 변경이 필요해 졌지만 이전 요소를 참조가 가능해져 데이터의 접근성이 향상되었다.
하지만 아직 여러개의 요소를 넘어 접근하는 것이 불가능하다. 이를 개선한 것이 이중 원형 연결리스트(doubly circular linked list)이다.
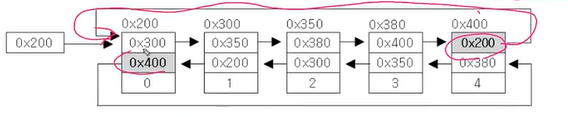
기존의 이중 리스트의 마지막과 첫 요소의 null을 활용하여 마지막 요소에는 첫 요소의 주소를 첫 요소에는 마지막 요소의 주소를 저장하여 데이터의 접근성을 향상시킨 것이다. 이중 원형 연결리스트가 존재하지만 자바에서는 이중 연결리스트로 구현이 되어 있다.
ArrayList와 LinkedList의 성능비교
1. 순차적으로 데이터를 추가/삭제 : ArrayList
2. 비순차적으로 데이터를 추가/삭제 : LinkedList
3. 접근시간(access time) : ArrayList
- 요소의 주소를 정확하 알 수 있기 때문
인덱스가 n인 데이터의 주소 = 배열의 주소 + n * 데이터 타입의 크기
| 컬렉션 | 읽기(접근시간) | 추가 / 삭제 | 비고 |
| ArrrayList | 빠르다 | 느리다 | 순차적인 추가삭제는 더 빠르다. 비효율적인 메모리 사용 (배열을 크기 잡아야 한다.) |
| LinkedList | 느리다 | 빠르다 | 데이터가 많을수록 접근성이 떨어진다. |
Vector 클래스
ArrayList는 기존의 Vector를 개선한 것이라 했다. Collections Framwork 도입전 지원하던 클래스로 ArrayList와 마찬가지로 Object[] 배열을 사용하며 같은 동작을 하며 사용할 수 있는 메소드는 거의 동일하다. 하지만 Vector은 항상 '동기화'를 지원하기 때문에 멀티 단일 쓰레드인 경우에도 동기화를 하기 때문에 ArrayList에 비해 성능이 느릴 수 있다는 단점이 있어 자주 사용되지 않는다.
Stack & Queue
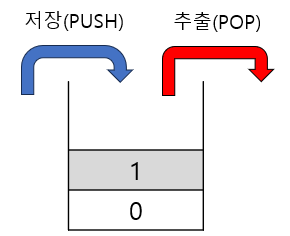
Stack(스택)
Stack은 LIFO(Last In First Out, 후입선출)방식으로 마지막에 저장된 것을 제일 먼저 꺼내게 된다. Stack은 Vector클래스를 상속받아 Vector에 있는 메소드를 이용하여 구현되어 있다.
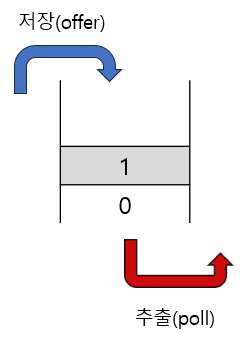
큐 (Queue)
FIFO(First In First Out), 제일 먼저 저장한 것을 제일 먼저 꺼내게 된다.
스택은 순차적으로 추가하며 순차적으로 삭제하기 때문에 스택을 구현하는데는 배열이 적합하지만, 큐를 구현하는데 배열을 사용한면 첫 요소 삭제시 많은 요소의 이동이 필요하기 때문에 보다 링크 리스트가 적합하다.
스택과 큐(Stack & Queue)의 메서드
Stack의 메서드
| 메서드 | 설명 |
| boolean empty() | Stack이 비어있는지 알려준다. |
| Object peek() | Stack의 맨 위에 저장된 객체를 반환, pop()과 달리 Stack에서 객체를 꺼내지는 않는다.(비었을 때는 EmptyStakcExcpetion) 발생) |
| Object pop() | Stack의 맨 위에 저장된 객체를 껀낸다.(비었다면 EmptyStakcExcpetion 발생) |
| Object push(Object item) | Stack에 객체(item)을 저장한다. |
| int search(Object o) | Stack에서 주어진 객체(o)를 찾아서 그 위치를 반환, 못찾으면 -1를 반환. (배열과 달리 위치는 0이 아닌 1부터 시작) |
Queue의 메서드
| 메서드 | 설명 |
| boolean add(Object o) | 지정된 객체를 Queue에 추가한다. 성공하면 true를 반환, 저장공간이 부족하면 illegalstateexception 발생 |
| Object remove() | Queue에서 객체를 꺼내 반환, 비어있다면 NoSuchElementException 발생 |
| Object element() | 삭제없이 요소를 읽어온다. peek와 달리 Queue가 비어있을 때 NoSuchElementException 발생 |
| boolean offer(Object o) | Queue에 객체를 저장, 성공하면 ture, 실패하면 false를 반환 |
| Object pool() | Queue에 객체를 꺼내서 반환, 비어있으면 null을 반환 |
| Object peek() | 삭제없이 요소를 일겅 온다. Queue가 비어있으면 null을 반환 |
Queue는 인터페이스 이다. Queue를 사용하기 위해서는 직접 구현하거나 구현한 클래스를 사용해야 한다.
Queue q = new LinkedList();
스택과 큐의 정리 필요
http://www.tcpschool.com/java/java_collectionFramework_stackQueue
'Java' 카테고리의 다른 글
| [JAVA] Comparator와 Comparable 인터페이스 (0) | 2023.11.08 |
|---|---|
| [JAVA] 컬렉션 프레임웍(collections framework)와 핵심 인터페이스 (0) | 2023.11.08 |
| [JAVA] 형식화 클래스 (0) | 2023.11.04 |
| [JAVA] 유용한 클래스(Math클래스, 래퍼클래스, Number클래스) (0) | 2023.11.04 |
| [JAVA] 날짜와 시간 그리고 Calendar 클래스 (0) | 2023.11.02 |